
大模型Token究竟是什么
分词器
像DeepSeek、ChatGPT这样的大语言模型LLM,都有一个“刀法精湛”的小弟——分词器
当大模型接收到一段文字,就让分词器将其切成很多个小块,切出来的每一个小块就是一个Token
切割举例
对于 我喜欢唱、跳、Rap和篮球 这句话,就可能切分为:我喜欢 唱 、 跳 、R ap 和 篮球
也就是说,一个汉字可以作为一个Token;一个字符也可以作为一个Token;两个字符和汉字也可以作为一个Token;甚至三个汉字构成的常见短语也可以作为一个Token
Token可以是一个字、两个字、三个字...也可以是一个单词或者半个单词...
输出Token
大模型在输出文本的时候,也是一个一个Token进行输出,看起来就像是在打字一样(找个AI问个问题,看他输出的样子就知道了)
整体看待,节省脑力
成语例子
为了通俗的理解与说明Token,可以借助“成语”的例子
现在要求你,快速读出下面5个字
- 旯
- 妁
- 圳
- 侈
- 邯
会发现我们并没有想象的那样“精通”汉字,需要反应一会甚至根本认不出来,但是如果放在词语、成语里呢?
- 犄角旮旯
- 媒妁之言
- 深圳
- 奢侈
- 邯郸学步
这样一下就看出来了。不过为什么呢?——因为我们的大脑会偷懒,这样整体看待字符可以节省脑力
句子例子
除了上面的成语例子,还可以用一个句子看看
看一下 “今天天气不错” 这句话
我们根本不会将字符全部独立看待:①今 ②天 ③天 ④气 ⑤不 ⑥错
而是划分为三个常见的、有意义的词:①今天 ②天气 ③不错 ;大脑要处理的内容就少了也简单直观了
人工智能也可“偷懒”
人脑可以“整体”看待部分字符,大模型也可以,所以就有了分词器,将文本切成大小合适的一个个Token,而不是一刀切全部用一个字符作为一个Token。
上下文窗口
分词越合理,不仅是大模型计算越轻松,更重要的是它能“看得更长”。大模型每次能接收的信息长度是有上限的(比如限制为 8000 个 Token)。如果“苹果”占2个Token,模型能处理的信息量就少;如果打包成1个Token,模型在同样的窗口大小内就能读取更多文本。这点明了分词效率与模型能力之间的直接关联
分词器的切分方式
不同的大语言模型有不同的分词器,分词的方法和结果都不一样,分词越合理大模型就越轻松
如何分词?
一种方式是这样的:大模型在大量接受文本输入之后,发现“苹果”这两个字经常一起出现,于是将其打包为一个Token,编号19416,这样下次看到“苹果”这两个字的时候直接认出19416编号的这个Token; 然后又发现“鸡”这个字经常出现,还可以不同的搭配其他字,于是将其打包为一个Token,编号76074; 又发现“ing”这三个字符经常一起出现,于是将其打包为一个Token,编号288; 又发现“逗号,”经常出现,于是将其打包为一个Token,编号14;
经过大量的统计收集,就得到了一个关于“Token-编号”的Token表,囊括了我们日常见到的各种字、词、符号
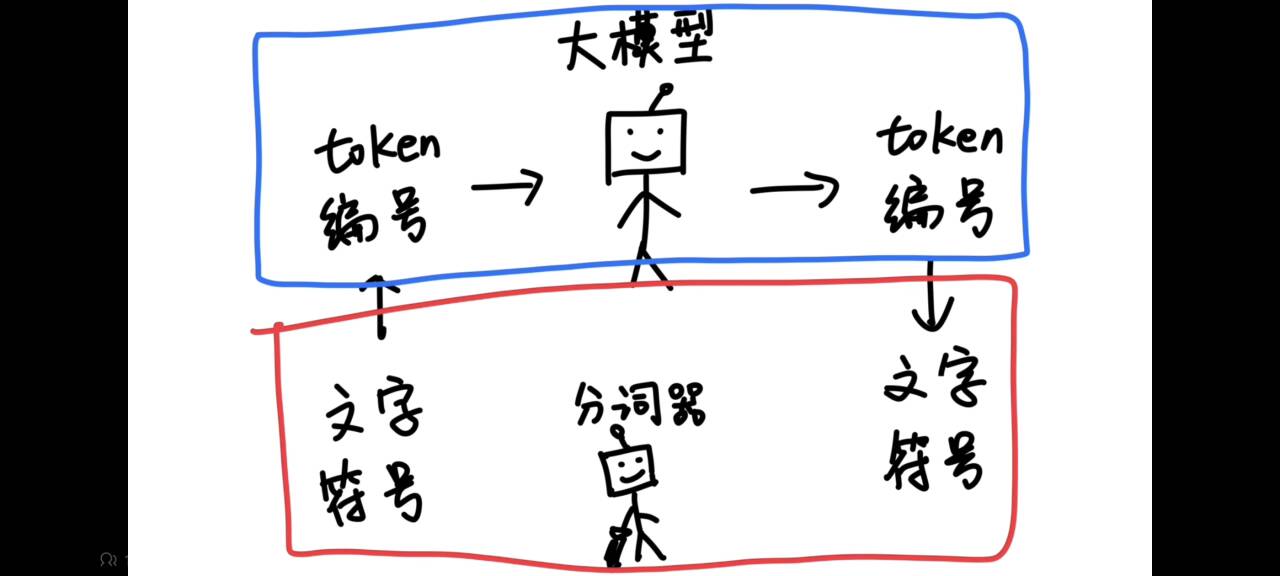
以编号形式输入输出
在有了Token表之后,对于任务的输入和输出,都只需要将其视为数字编号的组合,再由分词器根据Token表将这些数字编号的组合转换为人类可以看懂的文字和符号
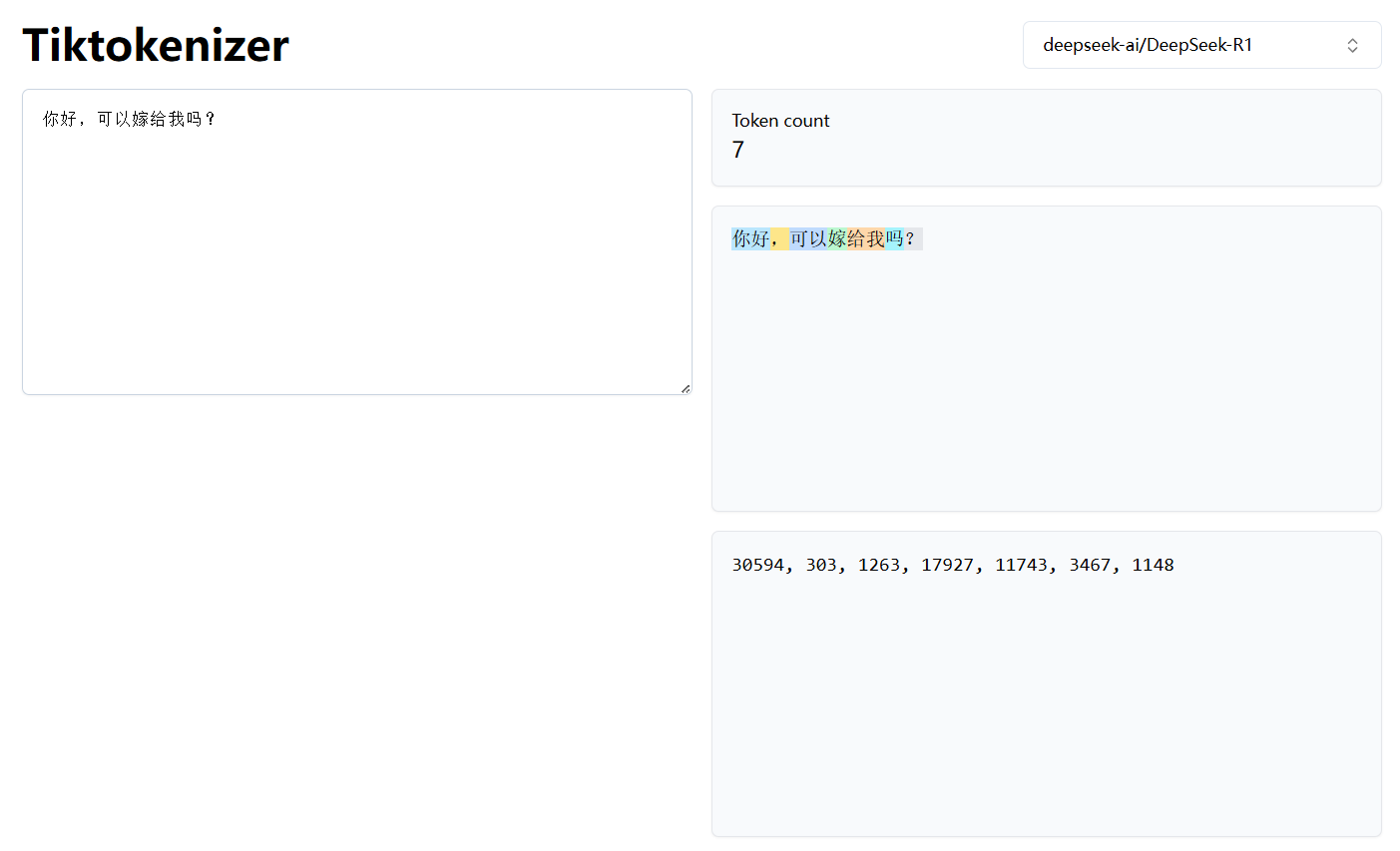
Tiktokenizer
网站:Tiktokenizer 可以查看不同模型分词后Token的编号
Summary:Token词元
所以,Token就是大模型世界里面的一块块积木,大模型能够理解和生成文字,就是计算了Token之间的关系,推出下一个Token最有可能的结果
这也是为什么几乎所有大模型公司都按照Token收费,因为Token的数量代表了背后的计算量
小插曲:token在人工智能之外的其他领域也经常出现,这是计算机领域的词源共性。计算机科学中,“Token”的本意就是“记号”或“具有独立意义的最小表意单元”